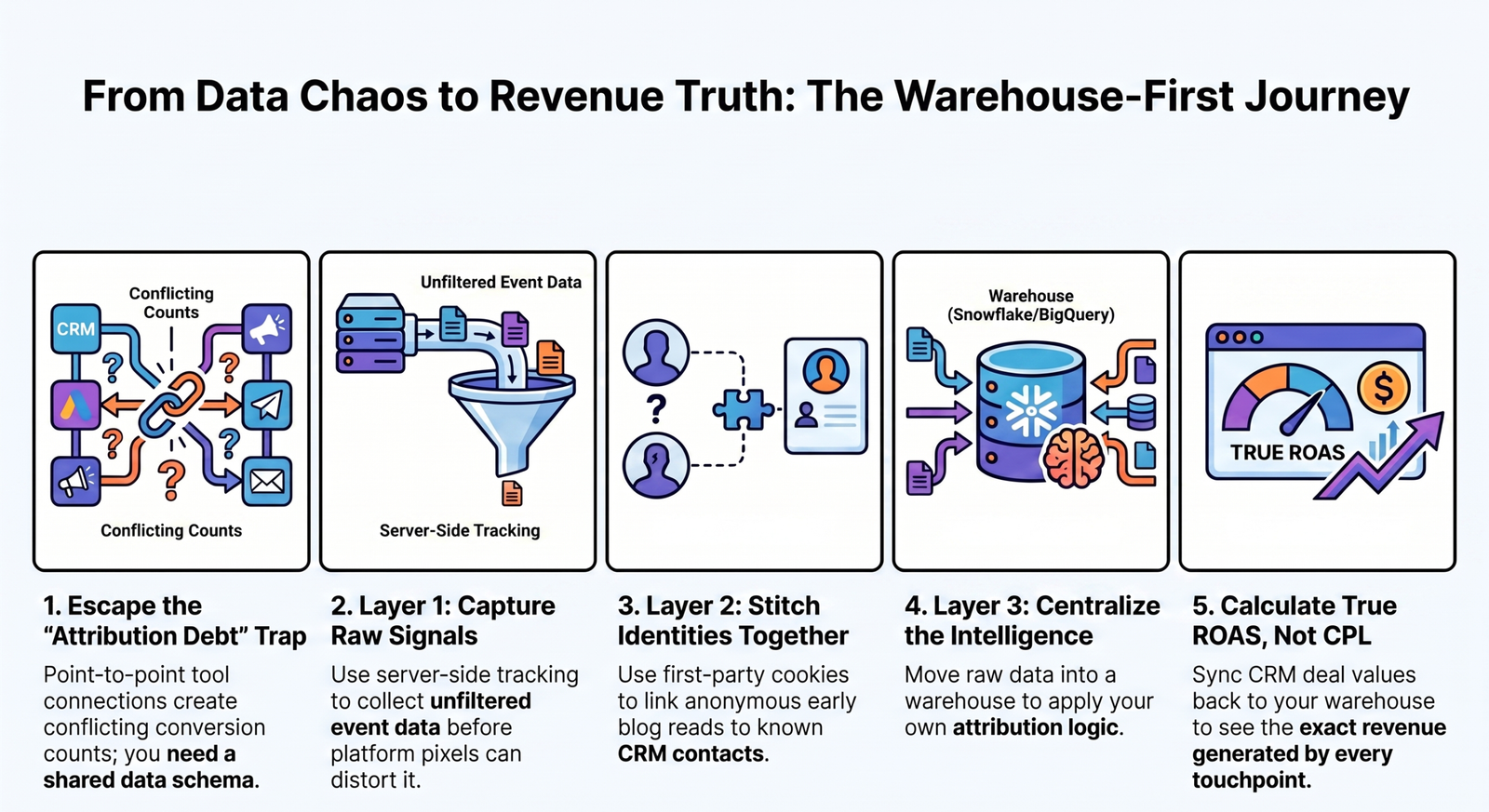
Most attribution setups fail not because the tools are disconnected, but because the data model underneath them was never designed. Connecting Meta to HubSpot to GA4 is not an architecture – it is a collection of point-to-point pipes that break every time a platform updates its API, changes its attribution window, or decides to count conversions differently. The first thing to connect is not your platforms. It is your data definitions. Build that foundation, and the integrations hold. Skip it, and you will keep debugging attribution every quarter.
Why Connecting Tools Is Not the Same as Owning Your Data
Tool connection is the beginning of data collection, not the end of it. Every integration you add pulls data into a system someone else controls, on terms someone else sets. That distinction matters more than most marketing teams realise – and it is why attribution keeps breaking for teams that have technically connected everything.
The Attribution Debt Problem: How Tactical Integrations Accumulate Into a Broken Schema
Attribution debt accrues quietly. You connect Meta to your CRM because the sales team wants to see lead source. You add a Google Ads integration because the CFO wants ROAS. You bolt on a GA4 connection because the analyst asked for it. Each integration solves a local problem. None of them were designed to talk to each other at the schema level – so they don’t. The result is three different conversion counts for the same campaign, depending on which dashboard you open.
The problem is not the integrations. It is that each one brought its own definition of a “conversion,” its own timestamp logic, and its own attribution window – and nobody reconciled them. That is attribution debt. It compounds. By the time you notice it, you are managing four systems of record, none of which agree.
Platform-Native Attribution vs. Warehouse-First Attribution: What You Are Really Choosing Between
When you use HubSpot’s attribution report or Meta’s Ads Manager as your source of truth, you are accepting their version of events. Meta will attribute conversions using a 7-day click, 1-day view window by default. HubSpot will use last-touch. GA4 will use data-driven attribution if you have enough volume, or last-click if you don’t. These are not neutral technical choices – they are each platform’s commercial interest expressed as a methodology.
Warehouse-first attribution means you pull raw event data from every platform into a system you control – BigQuery or Snowflake – and you apply your own attribution logic to your own data. You decide what a conversion is. You decide how credit is distributed. The platforms become data sources, not arbiters.
The Data Gravity Trap: Why Your Data Clusters Around Whichever Tool Your Team Uses Most
Data gravity is the tendency for data to accumulate around the tool with the most integrations – and for decisions to follow that data. If your team lives in HubSpot, HubSpot becomes the de facto source of truth for marketing performance, not because it is the most accurate, but because it is the most convenient. Every new integration gets evaluated by whether it connects to HubSpot, not by whether it feeds the cleanest data into a shared schema. Over time, the tool with the most gravity shapes your entire attribution model – by default, not by design.
The exit from the Data Gravity Trap is not switching tools. It is building a data layer that sits underneath your tools and treats each one as a contributor, not an authority.
The Three-Layer Marketing Data Stack
Connecting marketing data across tools requires understanding that three distinct functions are being performed simultaneously – and that collapsing them into one system is the root cause of most attribution failures.
Layer 1 – The Signal Layer (Ad Platforms, Website Events, Content Sessions)
The signal layer is where interactions happen: ad clicks, page views, blog reads, form submissions, video watches. Every platform you advertise on generates signal-layer data. So does your website. So does every piece of content you publish. The job of this layer is to capture events accurately and pass them upstream without loss or distortion.
Server-side event collection belongs here. When you run a GTM server container and send events from your server rather than the user’s browser, you are protecting the signal layer from browser restrictions, iOS privacy changes, and ad blockers. The events make it into your data model regardless of what the client-side environment looks like.
Content sessions belong in this layer too – and almost no team treats them that way. A blog reader who visits three articles over two weeks before submitting a demo request is generating signal-layer data at every visit. If those sessions are not captured as attribution events, the content team’s contribution disappears from every revenue report.
Layer 2 – The Identity Layer (CRM, CDP, First-Party Data, Known-User Stitching)
The identity layer is where anonymous sessions become known contacts. A user visits your site three times from an ad click, a Google search, and a direct visit. Those are three separate sessions in your analytics. The identity layer stitches them into one person – using email as the key when a form is submitted, or using a first-party cookie to maintain continuity across sessions before that point.
Your CRM is the authority on known users – who they are, what company they work for, what stage they are at in the pipeline. A CDP like Segment or RudderStack sits between the signal layer and the CRM, resolving identities in real time as events come in. First-party data – the email addresses, preferences, and behavioural signals your users have explicitly shared with you – is the asset that makes this layer resilient to third-party cookie deprecation.
Layer 3 – The Intelligence Layer (Warehouse, BI Tools, Attribution Models)
The intelligence layer is where raw signals and identity data become decisions. BigQuery or Snowflake holds the joined dataset – every touchpoint, every known user, every deal outcome. dbt transforms that raw data into clean attribution tables: one row per touchpoint, linked to one contact, linked to one deal, with a revenue value attached.
Your attribution model lives here, not in any individual platform. Whether you apply linear attribution, time decay, or a custom model built for your specific sales cycle, it runs against data you own – not data a platform has filtered through its own commercial logic.
Why Most Teams Collapse All Three Layers Into One – and What Breaks
The typical team uses their CRM for all three functions. HubSpot captures form submissions (signal), tracks contacts (identity), and reports on deal attribution (intelligence) – all in one tool. This works until it doesn’t. It breaks the first time a lead touches a channel HubSpot cannot see (a dark social share, a content session before the cookie fires, an offline event). Once you understand the three layers, you can see exactly where the gap is and fix the right thing.
How to Connect Your Ad Platforms Without Giving Them Your Attribution
The goal when connecting ad platforms is to extract their data, not to inherit their worldview. Ad platforms should feed your signal layer. They should not define what counts as a conversion.
Server-Side Event Collection: Capturing Signals Before They Touch Platform Pixels
Install your server-side tracking container first. Every significant event – page views, CTA clicks, form submissions, purchases – should fire from your server to your attribution system before any platform pixel sees it. This gives you a clean, unfiltered record of what happened on your site, independent of which ad platform a user came from.
Once your server-side layer is in place, you connect it to individual platforms as outputs – Meta receives the event, Google receives the event – but your warehouse has already received it first. The platform gets a signal to optimise with. You get the source record.
Conversion API (CAPI) and Offline Conversion Sync: Feeding Platforms Data Without Making Them the Source of Truth
Meta’s Conversions API and Google’s offline conversion upload exist to solve a real problem: the gap between what happens on your website and what the ad platform can see. CAPI lets you send conversion events directly from your server to Meta – bypassing browser restrictions entirely.
The distribution lens applies directly here. Conversion sync is not just a tracking fix – it is the mechanism by which your ad platform decides which audiences to find next. When you send back high-quality conversion signals, including deal values from your CRM, the algorithm optimises toward users who look like your best customers. When you send back every form fill regardless of quality, it optimises toward volume. What you feed the platform determines who it reaches. That is a distribution decision, not a tracking one.
UTM Schema Design: The Naming Conventions That Make Channel Data Joinable
UTM parameters are the connective tissue between your signal layer and your intelligence layer. A click from a Meta campaign arrives on your site with a UTM string that identifies the source, medium, campaign, ad set, and creative. If your UTM naming convention is inconsistent – if one campaign uses utm_source=facebook and another uses utm_source=meta – your data joins break. You end up with two rows where there should be one, and channel-level aggregations become unreliable.
Design your UTM schema once, enforce it across every platform, and never deviate. Use a shared taxonomy document. Treat UTM parameters as a data contract between your marketing team and your analytics infrastructure.
Attribution Window Conflicts: Resolving the Gap Between Meta’s 7-Day Click and GA4’s Last-Click Default
Meta attributes conversions to any ad interaction within a 7-day click or 1-day view window. GA4’s default is last-click, which means the conversion goes to whatever the user’s last session source was – often a branded search or direct visit that happened after the Meta ad did its job. These two methodologies will never agree, and they should not be expected to.
The resolution is not to pick one platform’s number. It is to build your own attribution table in your warehouse with the window that matches your actual sales cycle, and to use platform numbers only as channel-specific efficiency signals – cost per click, cost per impression – not as your source of conversion truth.
Connecting Your CRM to the Signal Layer
Your CRM is not an attribution tool. It is a revenue record. The moment you treat it as both, your attribution degrades – because CRMs are optimised for sales workflows, not event capture.
Mapping Pipeline Stages to Conversion Events: Which Stages Count and Which Don’t
Not every CRM stage change is a meaningful attribution event. Map only the stages that represent real commercial progress: lead created, marketing qualified, sales accepted, opportunity opened, closed won. Everything in between is a workflow state, not a conversion signal.
When you configure your attribution system to fire conversion events on these specific stage transitions, you create a clean signal chain: ad impression → site visit → form submit → MQL → closed won, each with a timestamp and a deal value. That chain is what makes pipeline attribution possible.
Identity Resolution: Stitching Anonymous Sessions to Known Contacts
The gap between anonymous and known is where most attribution models break. A user clicks a LinkedIn ad, reads two blog posts, and then submits a demo request three days later. The ad click and the blog sessions are anonymous. The form submission creates a known contact in your CRM. Identity resolution is the process of reaching back in time – using the first-party cookie set on the first visit – and attaching those anonymous sessions to the now-known contact.
When this works correctly, the LinkedIn ad gets credit for the sessions that happened before the form submission. When it does not, those sessions appear as direct or organic traffic, and LinkedIn’s contribution to the deal is invisible.
Revenue Sync: Making Deal Value a First-Class Field in Your Attribution Data
A conversion event without a revenue value is a vote. A conversion event with a revenue value is a fact. When your CRM syncs deal values back to your attribution system at the point of close, every touchpoint in that deal’s journey acquires a revenue weight. You can then calculate true ROAS – not cost per lead, but cost per dollar of closed revenue – at the campaign, ad set, and creative level.
Long Sales Cycle Attribution: How to Credit Campaigns That Converted 90 Days Later
A 90-day sales cycle means a campaign running today will not show revenue for three months. If your attribution window is 30 days, that revenue never gets credited to the campaign that generated it. Set your attribution windows to match your actual median sales cycle length. Pull that number from your CRM – median days from lead creation to close won – and use it as your window. This is one configuration change that will materially change which campaigns appear to be working.
Content Attribution: The Signal Most Teams Ignore
Organic content is the most systematically undercredited channel in B2B marketing. Not because it does not work, but because it is architecturally invisible in most attribution setups.
Why Organic Sessions Disappear From Attribution Models
Blog sessions typically arrive without a UTM parameter. They come from search engines, social shares, or direct links in Slack threads. Without UTM tagging, they appear as organic or direct traffic in GA4 – correct from a channel perspective, but invisible from an attribution perspective. When the eventual form submission gets attributed to the last paid click, the three blog posts the user read before that click disappear from the deal record entirely.
This is not a content problem. It is a data capture problem. The sessions happened. The intent was real. The signal was never collected.
How to Track Blog and SEO Sessions as Touchpoints in the CRM Deal Record
The fix requires three things working together. First, a persistent first-party cookie that identifies the user across sessions – set on their first visit and maintained until they identify themselves via a form. Second, an event that fires on every blog page load and writes that session to your attribution system as a “content touchpoint” event. Third, identity resolution that attaches those content touchpoints to the contact record when the form is eventually submitted.
When this is in place, a contact’s timeline in your CRM shows the full picture: LinkedIn ad click → blog post 1 → blog post 2 → blog post 3 → demo request. The content team’s contribution is no longer invisible.
The Content-to-Conversion Signal Chain: From First Read to Closed Deal
The full chain looks like this: a piece of content ranks organically and attracts a session from a prospect in your ICP. The first-party cookie fires and assigns an anonymous ID. The prospect reads two more articles over the following week – each session is logged as a content touchpoint against the anonymous ID. On their fourth visit, they submit a demo request. The form submission creates a CRM contact, triggers identity resolution, and retroactively attaches the three content sessions to that contact’s deal record. When the deal closes 60 days later, the revenue syncs back to the attribution system, and the content touchpoints receive weighted credit in your attribution model.
This chain does not require expensive tooling. It requires intentional data architecture.
Building the Data Layer You Own
Every layer described above feeds into one place: a data warehouse you control, with a schema you designed, running attribution logic you chose.
Choosing Your Warehouse: BigQuery vs. Snowflake for Marketing Data
BigQuery is the natural choice for teams already in the Google ecosystem – it integrates directly with GA4, is cheap for query-heavy workloads at moderate data volumes, and has strong native support for marketing datasets. Snowflake is the stronger choice for teams with complex multi-source data, larger volumes, or a need for fine-grained access control across departments. Both support the use case. The choice is an infrastructure and cost decision, not an attribution decision.
ELT Connectors: Fivetran and Airbyte as the Ingestion Layer
Fivetran and Airbyte are the pipes that move raw data from your source platforms into your warehouse. Fivetran is managed, reliable, and expensive at scale. Airbyte is open-source, self-hostable, and the right choice for teams with engineering capacity who want cost control. Either one connects to Meta, Google Ads, LinkedIn, HubSpot, Salesforce, and GA4 out of the box, and loads raw data into your warehouse on a configurable schedule.
dbt for Transforming Raw Signals Into Clean Attribution Tables
Raw data from your ELT connectors is not attribution-ready. It is source-system data: Meta’s ad impressions table, HubSpot’s contacts table, GA4’s events table. dbt transforms these raw tables into a unified attribution model – one table where every touchpoint for every contact is joined to the contact’s CRM record and the deal’s revenue outcome. This is where the Three-Layer Stack becomes a single queryable dataset.
When a CDP (Segment, RudderStack) Belongs in the Stack
A CDP belongs in your stack when identity resolution needs to happen in real time – before events reach the warehouse. Segment and RudderStack sit between the signal layer and the warehouse, resolving anonymous IDs to known users as events come in and routing enriched events to downstream destinations. If your sales cycle is short and identity resolution at the warehouse level introduces too much lag, a CDP closes that gap. For longer B2B sales cycles, warehouse-level resolution is usually sufficient.
Validating Your Connected Data: A Diagnostic, Not a Checklist
Validation is not about confirming things work. It is about understanding what breaks and why – before the broken data influences a budget decision.
What Broken Attribution Data Looks Like (and How to Read the Signs)
Three patterns indicate broken attribution. First: conversion counts that differ by more than 15% across platforms for the same date range, with no clear explanation tied to window differences. Second: a disproportionate share of conversions attributed to direct or organic when your paid spend is significant – this usually means UTM parameters are dropping or identity resolution is failing. Third: a disconnect between the leads your CRM shows from a campaign and the conversions the ad platform claims – a gap larger than 20% suggests a tracking or deduplication failure, not just a methodology difference.
Cross-Platform Reconciliation: How to Interpret Discrepancies, Not Just Detect Them
When Meta shows 120 conversions and your warehouse shows 95 for the same campaign and date range, the answer is not to pick one number. It is to diagnose the gap. Likely causes: Meta is including view-through conversions your warehouse excludes; your deduplication logic is collapsing events your warehouse treats as one; or the attribution windows differ. Work through each cause systematically. Document which discrepancy is expected (methodology difference) and which is not (tracking failure). Only the latter needs fixing.
Ongoing Data Quality: The Monitoring Setup That Catches Drift Before It Corrupts Decisions
Set automated alerts for three conditions: a platform integration returning zero events for more than four hours; conversion volume dropping more than 30% week-over-week with no corresponding spend change; and deal revenue failing to sync from the CRM within 24 hours of a stage change. These three alerts catch 90% of the data quality failures that would otherwise sit undetected until a monthly reporting cycle surfaces them.
FAQs
What is the difference between connecting marketing tools and owning your marketing data?
Connecting tools means authenticating integrations between platforms so data flows between them. Owning your data means routing that data into a warehouse you control, with a schema you designed and attribution logic you chose. Connected tools share data on each platform’s terms. Owned data gives you a single source of truth that no platform policy change or API update can compromise.
How do you connect CRM data to ad platform attribution without relying on platform-reported conversions?
Use your CRM’s deal close events as the authoritative conversion signal. When a deal reaches Closed Won, sync that event – with the deal value and the original lead source – to your warehouse. Apply your own attribution model against the touchpoint history stored there. Feed the ad platforms a conversion signal via CAPI or offline upload for optimisation purposes, but build your ROAS calculation from your own warehouse data, not from platform-reported conversions.
Why does attribution still break after connecting Meta, Google Ads, and a CRM?
Because the connections were built without a shared data schema. Each platform uses its own conversion definitions, attribution windows, and timestamp logic. Connecting them to each other does not reconcile those differences – it just creates more sources of conflicting data. Attribution holds when every platform feeds a single schema you own, with consistent conversion definitions and a single attribution window applied uniformly.
How do you include organic content sessions in marketing attribution?
Implement a persistent first-party cookie that fires on every page load, including blog and content pages. Log each content session as a touchpoint event in your attribution system against the anonymous user ID. When a visitor submits a form, use identity resolution to attach their prior anonymous sessions to their new CRM contact record. The content touchpoints then appear in the deal’s timeline and receive credit in your attribution model.
What does a warehouse-first marketing data architecture look like compared to tool-native attribution?
Tool-native attribution lives inside a single platform – HubSpot, Meta, GA4 – and reflects that platform’s methodology. Warehouse-first architecture extracts raw data from every platform via ELT connectors like Fivetran or Airbyte, loads it into BigQuery or Snowflake, transforms it with dbt into a unified attribution table, and applies attribution logic you define. The output is a dataset where every touchpoint, every contact, and every deal outcome are in one place – joinable, auditable, and owned entirely by you.